Here's something most teams get wrong: they use the same model for every single turn in a conversation. Same capability, same cost, whether the user just said "hello" or asked you to redesign their entire database schema. But the first few exchanges are where all the leverage is. That's when the assistant needs to actually understand the problem. After that? Most of the work is just following the plan. So why pay for top-tier reasoning on every single turn?
The Strategy: Smart Framing, Cheap Execution
Think about it. The user describes their problem, probably badly. The assistant has to figure out what they actually mean, fill in the gaps, spot the constraints they forgot to mention. If it gets this wrong, everything downstream is garbage. That's where you want your best model.
A stronger reasoning model is way better at decomposing the problem, calling out assumptions, building a structured plan, and catching edge cases. Once that scaffold exists in the conversation, a cheaper model can take over and do fine. It can expand sections, write code within the architecture that's already been decided, generate docs, iterate on details.
It's basically online distillation. The smart model seeds the conversation with quality, and the lighter model rides those rails.
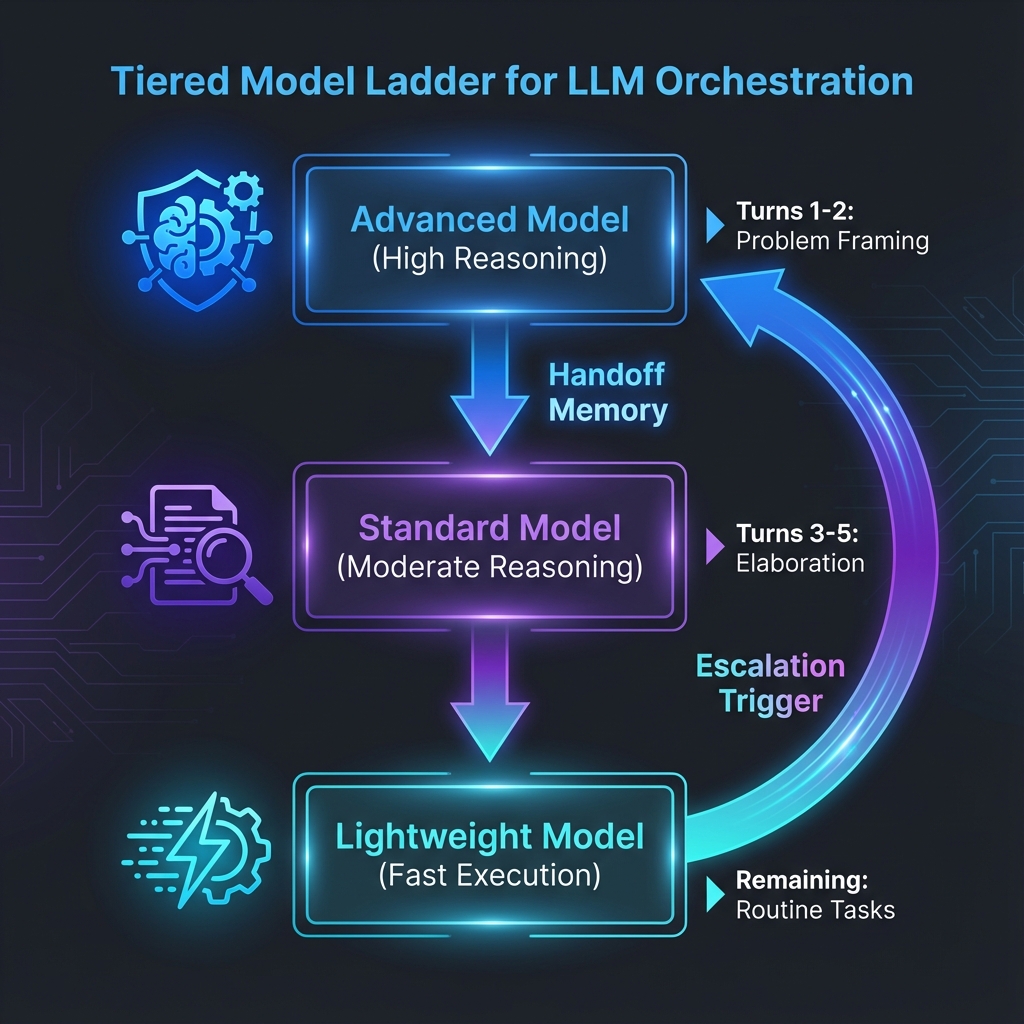
Example Ladder Configurations
A simple ladder might look like this: use a high reasoning model for the first one or two responses to handle problem framing and planning, then switch to a lightweight model for routine continuation like execution, elaboration, and reformatting. Escalate back to the high reasoning model when complexity spikes.
A more aggressive approach uses a step down pattern across multiple model tiers. For example, two responses from the advanced tier, three responses from a mid tier, then the remainder from a lightweight tier.
Whether multiple steps are worthwhile depends on your specific environment: how large the quality gaps are between tiers, how expensive each tier is, and how risky model handoffs are for your domain.
Why This Works: The Guide Creates a Stable Scaffold
The high reasoning model's job is not to do everything. Its purpose is to produce artifacts that lighter models can reliably follow. These artifacts include:
Goal Statement
A clear, one sentence description of what the user is trying to achieve. This anchors all subsequent responses.
Constraints and Non Goals
What must be true, and what is explicitly out of scope. Lightweight models tend to wander less when boundaries are clearly stated.
Assumptions
If any assumption is wrong, it should be surfaced early. This prevents compounding errors downstream.
Plan
A small number of steps that define how the assistant will proceed. This gives the lighter model a roadmap to follow.
Format Contract
Output style expectations: bullets, sections, diff format, or specific templates. Consistency matters for user experience.
If these items exist in the conversation early, a lightweight model can stay in the lane and deliver acceptable answers for much less cost.
The Critical Engineering Detail: Managed Handoffs
Model switching is not free. Each handoff can cause formatting drift, dropped constraints, loss of definitions or terminology, and lower factual discipline.
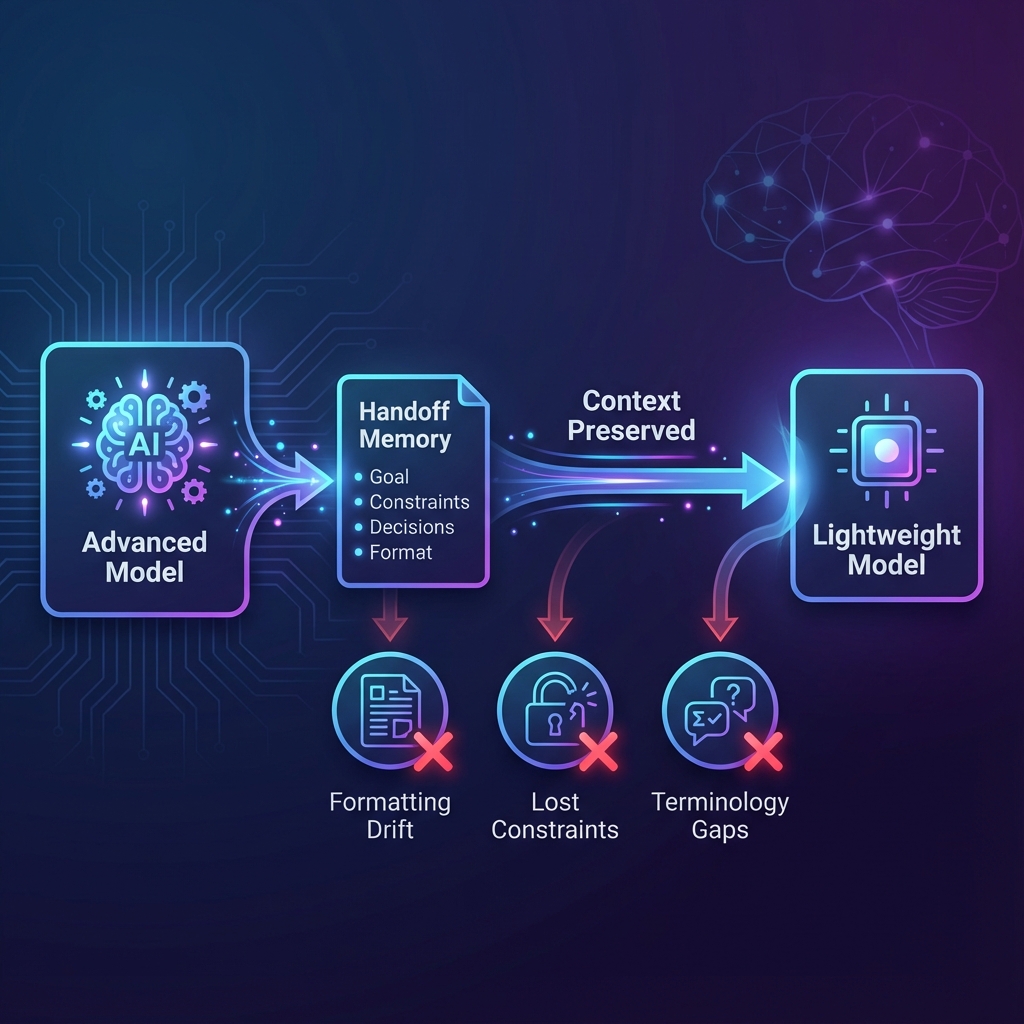
A robust implementation introduces a handoff memory: a compact summary injected into the prompt whenever the system transitions to a different tier. This memory should include the goal, constraints, decisions made so far, open questions, and the expected output format.
This memory should be short, stable, and updated periodically as the conversation evolves.
Routing Strategy: Beyond Simple Turn Counting
A fixed rule like "switch after N turns" is simple but brittle. A better approach combines a default ladder with escalation triggers.
Default Phases
Onboarding phase uses the high reasoning model for the first one or two turns to clarify and plan. Execution phase uses lighter models to produce deliverables within the established scaffold.
Escalation Triggers
Escalate back to the high reasoning tier when the user changes the goal mid conversation, when constraints conflict with each other, when the assistant detects missing information it cannot safely infer, when the topic becomes high stakes such as security, legal, or medical matters, when a deep debugging or architecture turn appears, or when the lighter model signals low confidence.
After an escalation turn resolves the ambiguity or sets a new plan, transition back to the lighter tier.
Measuring Success: Quality and Efficiency
To validate this approach, you need to measure both output quality and system efficiency.
Quality Metrics
Track correctness and completeness through human review or rubric scoring. Monitor instruction following by checking constraint coverage. Measure hallucination rate by counting unsupported claims. Count self corrections where the model says something like "I was wrong earlier."
Efficiency Metrics
Track total tokens per resolved task. Monitor latency distribution. Count back and forth turns until completion. Track escalation frequency to understand how often lighter models need rescue.
A particularly telling metric is first turn alignment rate: how often do the first one or two answers correctly capture the user's intent and constraints? If the high reasoning model improves first turn alignment, downstream turns usually become cheaper and shorter.
Common Failure Modes and Mitigations
Wrong Early Framing Gets Amplified
If the high reasoning model chooses the wrong approach confidently, lighter models may follow it without questioning. Mitigation: require an explicit assumptions block early, and instruct later models to flag assumption violations immediately.
Style and Structure Drift Across Tiers
Different models may vary in formatting and verbosity. Mitigation: put a strict output contract into the system prompt and include a short format specification in the handoff memory.
Lighter Models Invent Details to Fill Gaps
Models with lower reasoning capability may be more willing to guess rather than ask. Mitigation: enforce a rule like "ask or list required inputs; do not fabricate" and keep a visible list of unknowns.
Too Many Handoffs
Every switch is a chance to lose context. Mitigation: prefer one handoff from high reasoning to lightweight plus escalation triggers, unless your cost model strongly rewards multiple steps.
When This Pattern Fits Well
This approach works well when early problem framing is genuinely difficult, when later steps are mostly repetitive execution, when you can define a stable output contract, and when you can tolerate occasional escalations back to the high reasoning tier.
It is less effective when every turn requires deep reasoning, when the user keeps changing goals mid conversation, or when strict coherence across many turns is the primary requirement.
Summary
The tiered model ladder is a practical way to improve response quality while reducing total cost. Use a high reasoning model to establish the scaffold. Hand off to a lightweight model for routine continuation. Escalate on demand when complexity spikes.
The key insight is that it is not the ladder itself that matters most. What makes this pattern work is the handoff memory and routing triggers that preserve correctness and consistency when moving between capability tiers.